MADL!AR
Code is cheap, show me the PPT!
首页
分类
Fragment
关于
Argo Workflows 初见
分类:
k8s
发布于: 2023-08-18
## 一、简介 Argo Workflows是一个用于在Kubernetes上编排并行作业的开源容器本地工作流引擎。Argo Workflows以Kubernetes CRD(自定义资源定义)的形式实现。主要特性: * 定义工作流,其中每个步骤都是一个容器 * 将多步骤工作流建模为任务序列,或者使用有向无环图(DAG)捕获任务之间的依赖关系 * 使用Argo Workflows在Kubernetes上轻松地运行机器学习或数据处理的计算密集型作业,可以在更短的时间开销内完成 ## 二、安装 参考 [argo: quick-start](https://github.com/argoproj/argo-workflows/blob/master/docs/quick-start.md) 安装过程较为简单,安装脚本执行完毕后,会在指定的namespace下多出两个pod ``` root@argo-control-plane:/# kubectl get po -n argo NAME READY STATUS RESTARTS AGE argo-server-5974946f76-5h9bt 1/1 Running 2 (16h ago) 16h workflow-controller-f58c79-ljtff 1/1 Running 2 (16h ago) 16h ``` 实际上它们是两个deployment管理的pod,分别对应controler和server,前者负责所有协调工作,后者提供 API 服务,比如一些web hook和事件监听机制。 argo 将所有的 workflow 存储到 etcd 中,不依赖 MySQL等数据库,因此在上述列表中没有存储相关的POD。此机制会限制每个resource最多占用1MB的空间,如果经压缩后依然超过1MB,argo会尝试放到别处,比如SQL 数据库里。所以在argo的config map中有一个可选参数,用于配置SQL存储服务,支持PostgressSQL或MySQL,如果未配置,那么此时就会触发一个“offload node status is not supported”错误。配置如下: ```yaml #at: https://argoproj.github.io/argo-workflows/workflow-controller-configmap.yaml # Optional config for mysql: # mysql: # host: localhost # port: 3306 # database: argo # tableName: argo_workflows # userNameSecret: # name: argo-mysql-config # key: username # passwordSecret: # name: argo-mysql-config # key: password ``` 有两种方式可以操作argo,CLI或web页面。给argo-server配置好端口转发后,可以通过浏览器访问:  ## 三、架构与核心概念 工作流(workflow)及其生成的容器运行在哪个ns下,取决于安装时的配置,采用默认的安装方式,则其都会在`argo`下执行。比如提交了quick start页的示例workflow并等待其完成之后,可以看到argo下多了一个pod: ``` NAME READY STATUS RESTARTS AGE argo hello-world-s6d5s 0/2 Completed 0 36h ``` argo的设计架构可以参考这里 [argo: architecture](https://argoproj.github.io/argo-workflows/architecture) ,每个Step和每个DAG Task都会生成一个Pod,每个Pod由3个容器组成:  * main容器运行用户指定的映像 * init容器是一个InitContainer,获取 artifact 和参数,供main容器使用 * wait容器执行清理,保存参数和 artifact 控制器架构 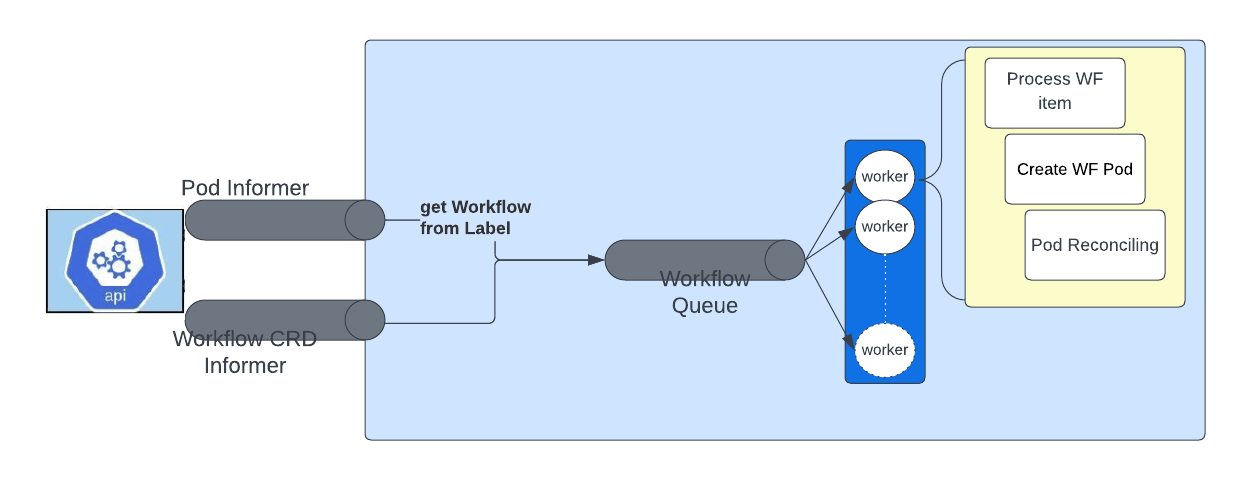 ## 四、工作流(workflow) 示例: ```yaml apiVersion: argoproj.io/v1alpha1 kind: Workflow metadata: generateName: hello-world- # Name of this Workflow spec: entrypoint: whalesay # Defines "whalesay" as the "main" template templates: - name: whalesay # Defining the "whalesay" template container: image: docker/whalesay command: [cowsay] args: ["hello world"] # This template runs "cowsay" in the "whalesay" image with arguments "hello world" ``` 要执行的工作流程在Workflow.spec(注意首字母大写)字段中定义。工作流规范的核心结构是一个列表templates和一个entrypoint. templates可以粗略地认为是“函数”:它们定义要执行的指令。该entrypoint字段定义“主”函数是什么——即将首先执行的模板。 其中template有6种类型,分属两个类别: * 模板定义:在容器中定义要执行的工作 * 模板调用器:用于调用或执行控制 ### (一)模板定义 #### 1. Container 定义一个容器,规范与Kubernetes 容器规范相同: ```yaml - name: whalesay container: image: docker/whalesay command: [cowsay] args: ["hello world"] ``` #### 2. Script 规范与容器相同,但添加了允许就地定义脚本的字段:`source`。该脚本将保存到文件中并为您执行。根据调用方式不同,脚本的结果会自动导出到Argo 变量,或{{tasks.<NAME>.outputs.result}}或{{steps.<NAME>.outputs.result}}。 ``` - name: gen-random-int script: image: python:alpine3.6 command: [python] source: | import random i = random.randint(1, 100) print(i) ``` #### 3. Resource 不同于k8s的资源,这里定义的是直接对集群资源执行的操作。可用于获取、创建、应用、删除、替换或修补集群上的资源。 此示例在集群上创建一个ConfigMap: ``` - name: k8s-owner-reference resource: action: create manifest: | apiVersion: v1 kind: ConfigMap metadata: generateName: owned-eg- data: some: value ``` #### 4. SUSPEND 挂起模板将挂起执行一段时间或直到手动恢复。可以从 CLI(使用argo resume)、API 端点或 UI 恢复挂起的模板,个人理解可以用于debug或者特殊情况下的同步。 ```yaml - name: delay suspend: duration: "20s" ``` ### (二)模板调用器 #### 5. Step step模板通过一系列步骤定义任务。模板的结构是“列表的列表”。外部列表将顺序运行,内部列表将并行运行。想逐一运行内部列表,可以使用[同步](https://argoproj.github.io/argo-workflows/fields/#synchronization)功能。也可以设置多种选项来控制执行,例如when:有条件地执行步骤的子句。 在此示例中,step1首先运行。一旦完成,step2a将step2b并行运行: ``` - name: hello-hello-hello steps: - - name: step1 template: prepare-data - - name: step2a template: run-data-first-half - name: step2b template: run-data-second-half ``` #### 6. DAG 定义依赖关系: ``` - name: diamond dag: tasks: - name: A template: echo - name: B dependencies: [A] template: echo - name: C dependencies: [A] template: echo - name: D dependencies: [B, C] template: echo ``` 此外,在argo workflow的用户指南中,还有几种特殊的 template types。 * 用于发起HTTP请求的[HTTP模板](https://argoproj.github.io/argo-workflows/http-template/) 在官方示例中根据`inputs.parameters`中的`url`参数发起了一个请求。至于如何将HTTP的response保存到argo变量或输出输入的产物中,没找到相关介绍;对于异常捕获、重试机制也未有提及。此类模板完全可以通过Script或Container模板替代。 * 容器集模板 在一个pod中定义多个容器,以安排到同一台主机上执行。 优点: * 可以调度到同一台主机,可以使用宿主机的本地目录同步数据 * 具有依赖关系,实现DAG的同等功能 主要的缺点是开销比DAG大,原因有以下几点: * 该POD申请的资源为所有容器申请的总和,如果有依赖关系,则某些容器在等待的时候,也占用资源 * 所有容器都并行启动,等到某些依赖关系满足时,argo才会在容器中启动主进程 * Data Sourcing and Transformations 用于将一些外部资源引入到workflow当中,并且可以插入一些数据转换的操作